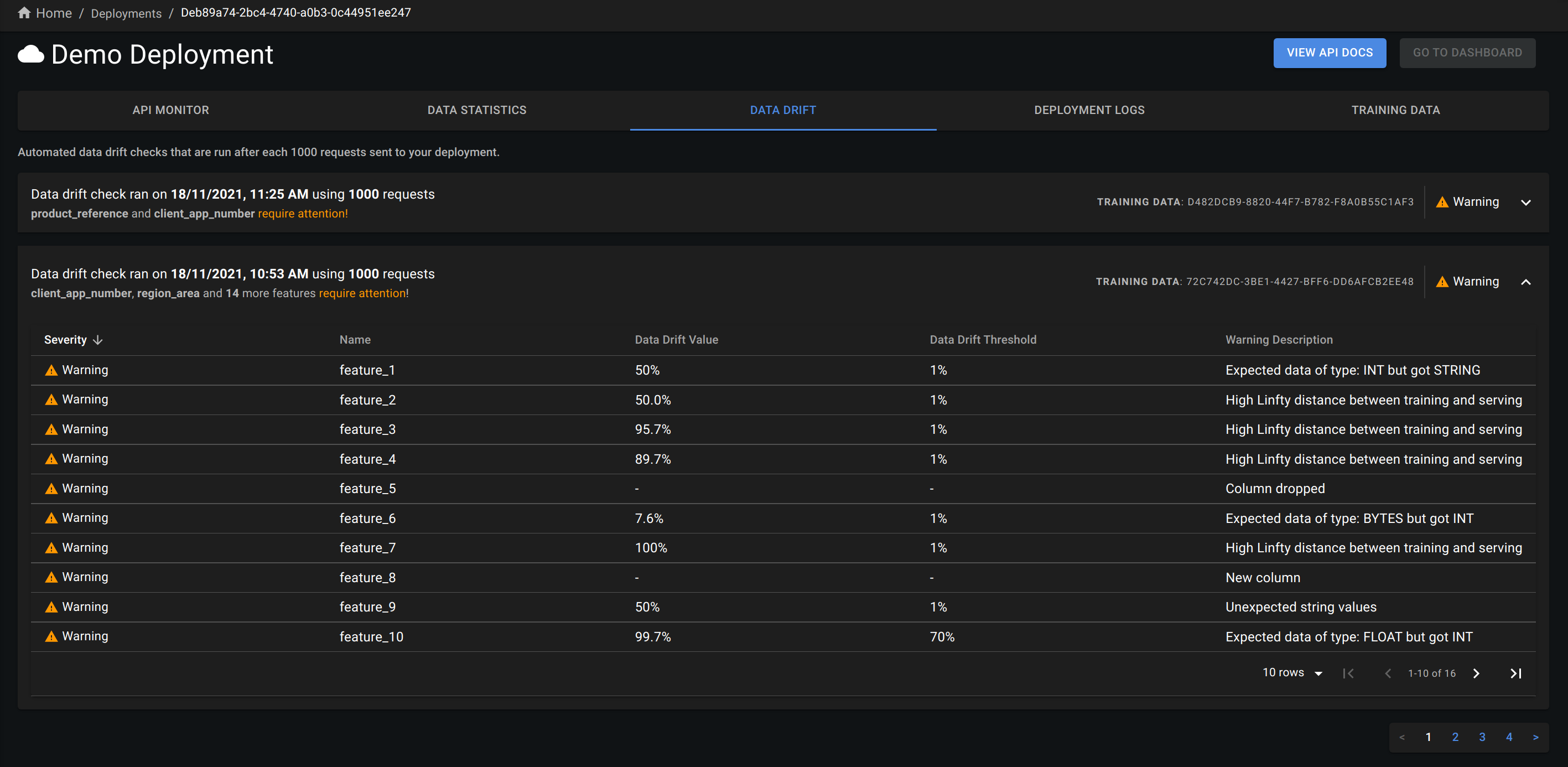
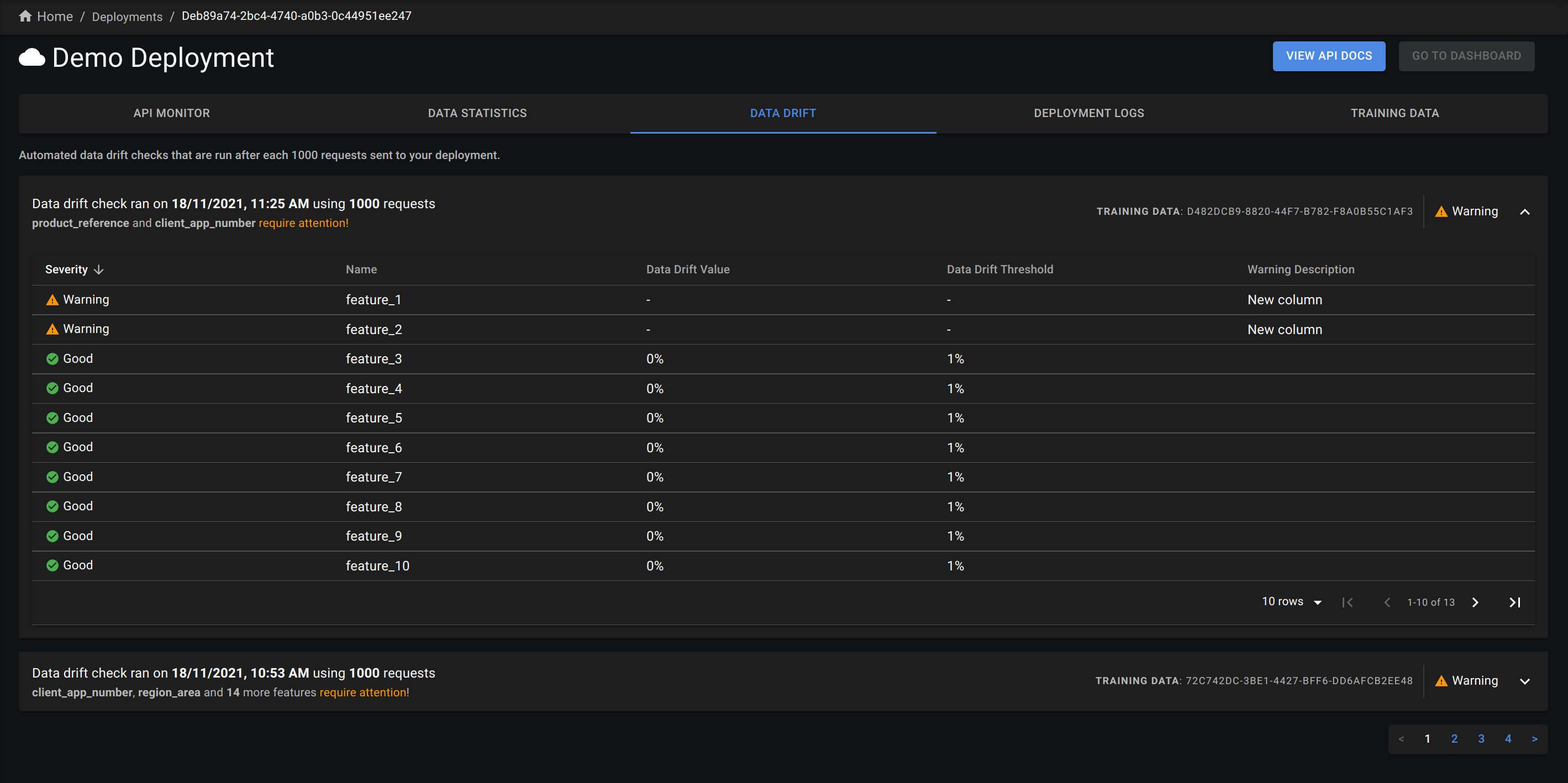
Data Drift Reports
Perhaps one of the most important metrics to monitor for ML models in production is data drift. Put simply, data drift measures how different the statistical distribution of the production data is from training data. This is important because the underlying assumption of ML models is that production data is statistically equivalent to the training data, i.e., it mimics the same patterns and distributions, so if that is not the case, then the predictions are considered unreliable.
Training Data
To calculate data drift, you should upload your training data as CSV file. Make sure the format of the training data matches the incoming requests, i.e., same column names. Discrepancies between the training data and serving data will be flagged in the drift summary. Once training data is uploaded, data drift will be calculated every 1000 prediction requests.
You don't have to upload the entire training dataset, a sample that captures the dataset's distribution will be sufficient.
The methods used to calculate data drift are L-infinity distance for categorical features and Jensen-Shannon divergence for numeric features.